7 Key Differences Between Data Lake and Data Warehouse
Data Lake vs Data Warehouse
A data lake is a location where new data can enter without any hurdles. Since any kind of data can reside in a data lake, it is a great source to unearth new ideas and experiment with data. However, due to this openness, it suffers from a lack of meaningful structure. The larger business audience may find that the data lake is a mess. This is where the scalability traits of the data warehouse gain significance. In data warehousing, we try to match dimensions and measures into queryable components that are consistent. This makes it easier for an ever-scalable audience to consume this data.
Let us now take a deep dive and compare the properties of a data lake and a data warehouse.
Read more: How Data Warehousing Adds Value To Data Visualization & Reporting
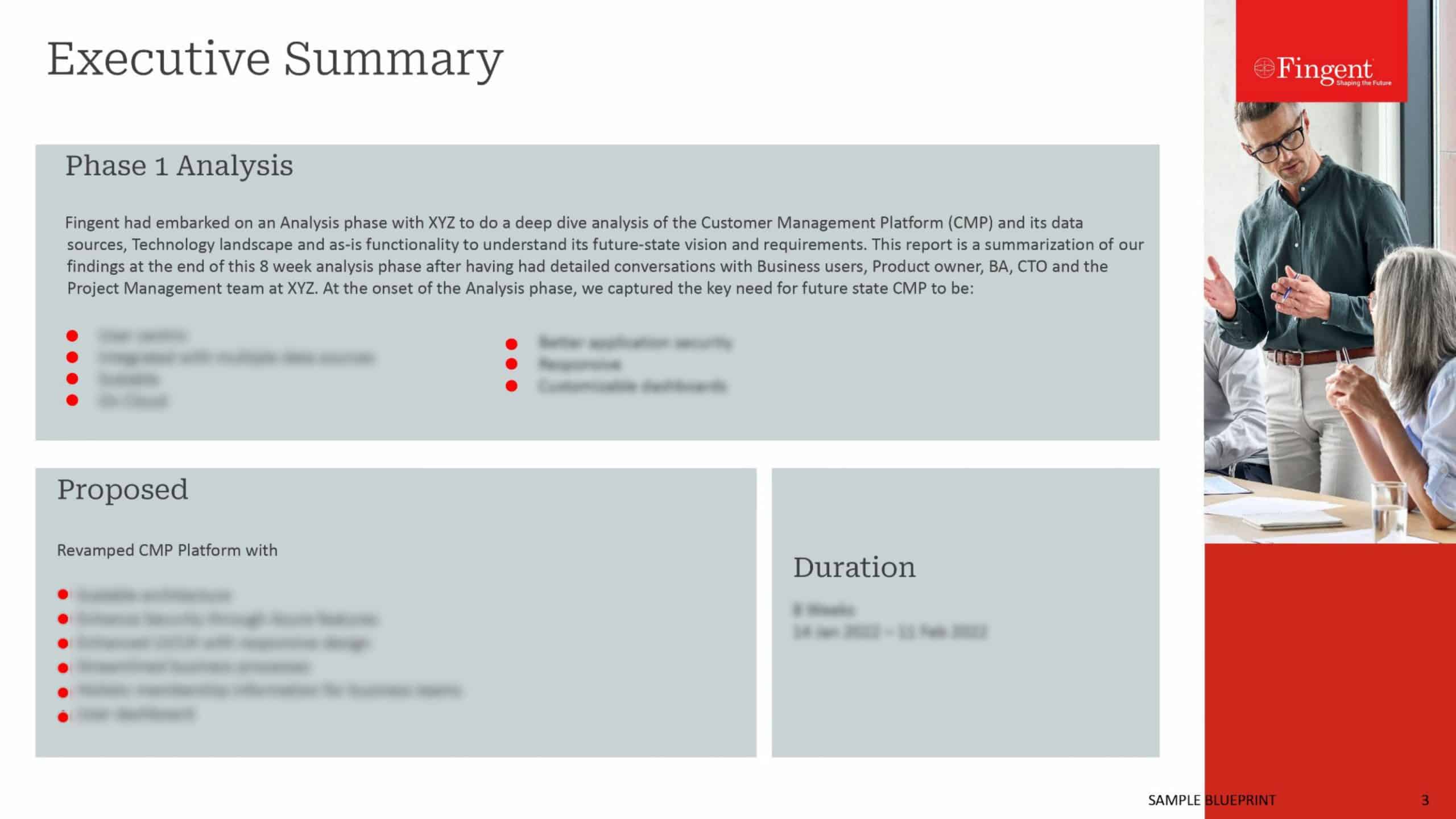
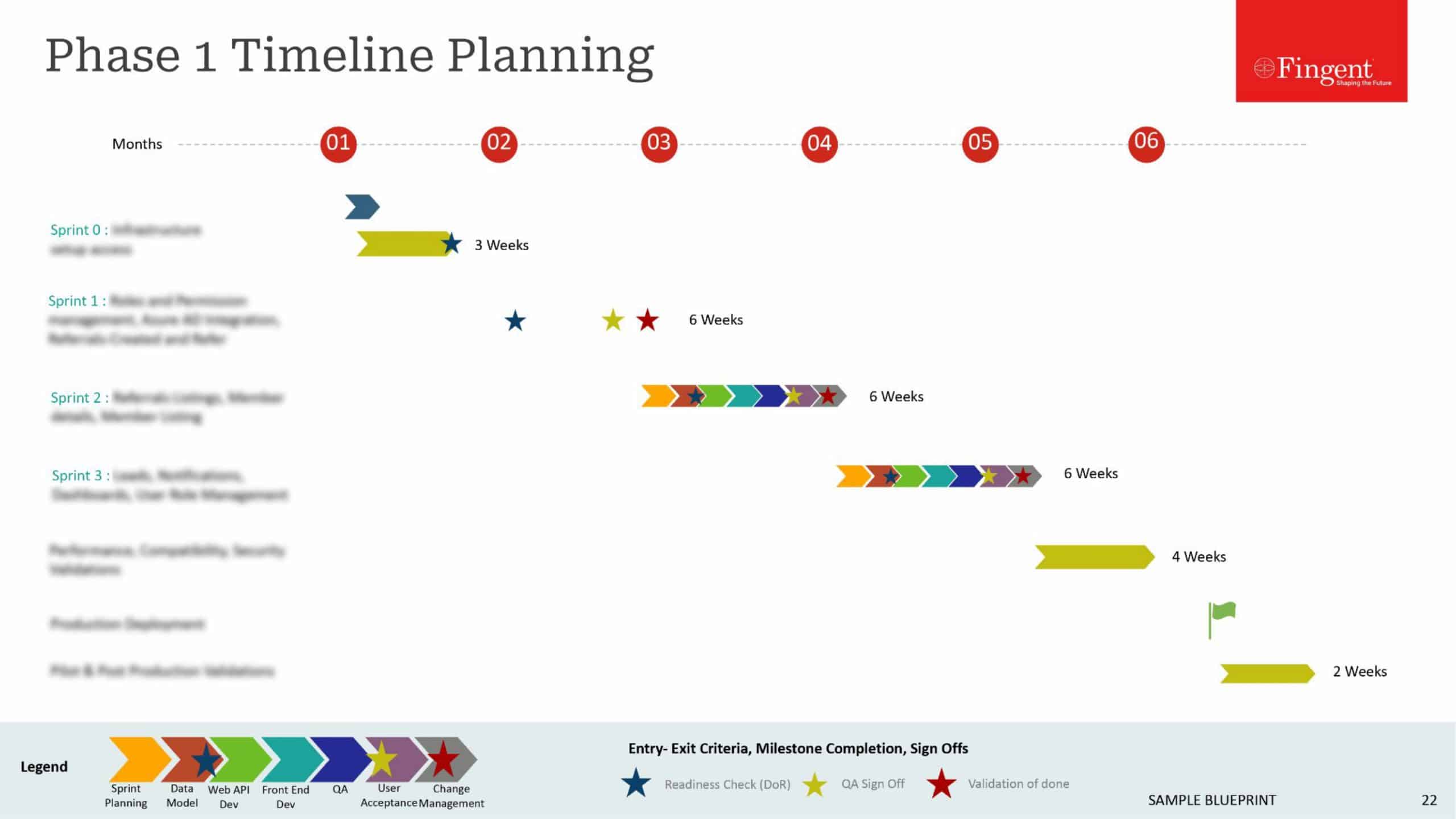
7 key differences between data lake and data warehouse
1. Type of Operation:
- A data warehouse is used for Online Analytical Processing (OLAP). This includes running reports, aggregating queries, performing analysis, and creating models such as the OLAP model based on whatever you want to do. These operations are carried out typically after your transactions are done. For example, you want to check all the transactions done by a particular client. Since the data is stored in a denormalized format, you can easily fetch the data from a single table and showcase the required report.
- A data lake is used typically to perform raw data analysis. All the raw data i.e XML files, images, pdf, etc. are just gathered for further analysis. While capturing data, you don’t have to define the schema. You may not know how this data can be used in the future. You are free to perform different types of analytics to uncover valuable insights.
2. Cost of storing data:
- In data warehouses, the cost of data storage is high. This is because the software used by these data warehouses are expensive. Additionally, the cost of maintenance is also high since it consists of power, cooling, space, and telecommunications. Another point to consider is that since a data warehouse contains large amounts of data in a denormalized format, it tends to take up a lot of disk space.
- Contrarily, in data lakes the cost of data storage is low. They use open-source software which costs less. Also since the data is unstructured, data lakes can scale to high volumes of data at low cost.
3. Schema:
- Data warehouses use schema-on-write. Before storing the data, it has to be transformed and provided for application in analytics and reporting. You need to know for what purpose you’ll be using the data prior to importing it into the data warehouse. As new requirements arise, you may have to reevaluate the models that were defined earlier.
- On the other hand, data lakes employ schema-on-read. Without the necessity of a single schema, users can store any kind of data in the data lake. They can discover the schema later while reading the data. This means different teams can store their data in the same place without relying on the IT departments to write ETL jobs and query the data.
4. Data Quality:
- A data warehouse contains high-quality data. As the data undergoes extreme curation before storage, it can be considered as the central version of the truth.
- A data lake contains raw data that may or may not be curated.
Read more: Data Visualization vs. Data Analytics – What’s the Difference?
5. Users:
- Typically business professionals who deal with reporting use data warehouses. Again, since the operation costs of a data warehouse tend to be higher, large and established organizations that deal with tons of data opt for it.
- Data scientists and analysts generally use data lakes. With raw data the possibilities are endless. They can perform various types of analytics to glean insights and identify patterns to convert the data at hand into valuable information.
6. Security:
- Data warehouses tend to store extremely sensitive data for reporting purposes. These could be compensation data, credit card information, healthcare data, and so on. The data security for data warehouses is mature and robust since this technology has been around for quite a while now. Only authorized personnel can access the data warehouse.
- Data Lake is a relatively new technology and hence data security is still evolving. As mentioned, a data lake is created using open source technologies. Therefore its data security is not as great as that of a data warehouse.
7. Technology:
- Data warehouse applications use relational database technologies. This is because relational database technologies support quick queries against structured data.
- The Hadoop ecosystem is well-aligned to the data lake approach because of its agility. It can easily scale to large volumes and can handle any structure of data.
Read more: Power BI or Tableau: Which is the better choice for your business
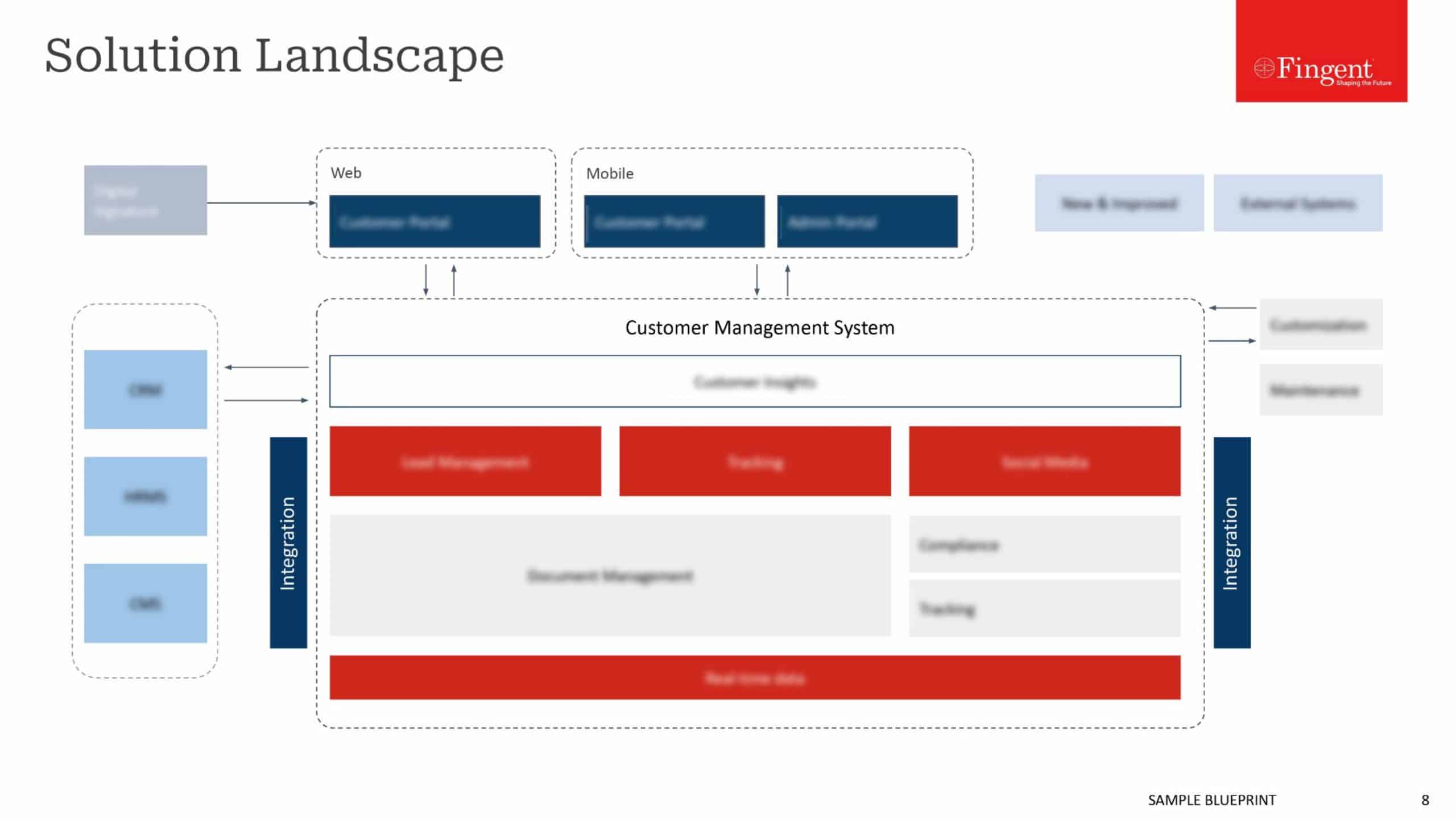
How both data lake and data warehouse can go hand in hand
Both data lake and data warehouse are the principal constituents of modern data architecture. A data lake usually serves as the starting point from where organization-wide data is onboarded. It is also the stage at which the data warehouse structures its data. An organization that incorporates both data lake and data warehouse will exhibit the traits of entrepreneurship and diligence, which means the organization will be both open-minded and scalable.
The BI industry has tools that cater to highly unstructured data lakes that enable open-minded discovery. Also, there are tools that are designed to scale as a structured information delivery platform concurrently with your data warehouse. Though these tools oppose one another, they have very little in common. They are purpose-built according to the needs of an organization. So before choosing a tool you need to determine which one would be right for your needs and help your organization grow. Contact us now for more information!
Stay up to date on what's new

About the Author

Recommended Posts

02 Feb 2022 B2B
Taking A Look Back At Industry Tech!
We saw great challenges overcome, extraordinary feats accomplished as businesses fought tooth and nail to keep their doors open. It has also been a time of great innovation. While the……

15 Oct 2021
Data and AI: How It Has Transformed Over The Years And Trends To Watch Out For!
Undoubtedly, data is what we see almost everywhere, and it is enormous. And it doesn’t stop there, it is growing continuously at a level beyond imagination! Let’s have a look……

04 Aug 2021
Ensure Business Continuity with SAP S/4HANA Selective Data Transition Approach
Streamlining SAP S/4HANA Migration with Selective Data Transition Though the COVID-19 pandemic accelerates digital adoption among industries, the journey towards Intelligent Enterprise can be complex. Typically, this begins with establishing……

15 Dec 2020 Manufacturing
Top 10 Technologies That Will Transform Manufacturing in 2024
Manufacturing technologies set to hold the reins From big data analytics to advanced robotics to computer vision in warehouses, manufacturing technologies bring unprecedented transformation. Many manufacturers are already leveraging sophisticated……
Featured Blogs








Stay up to date on
what's new