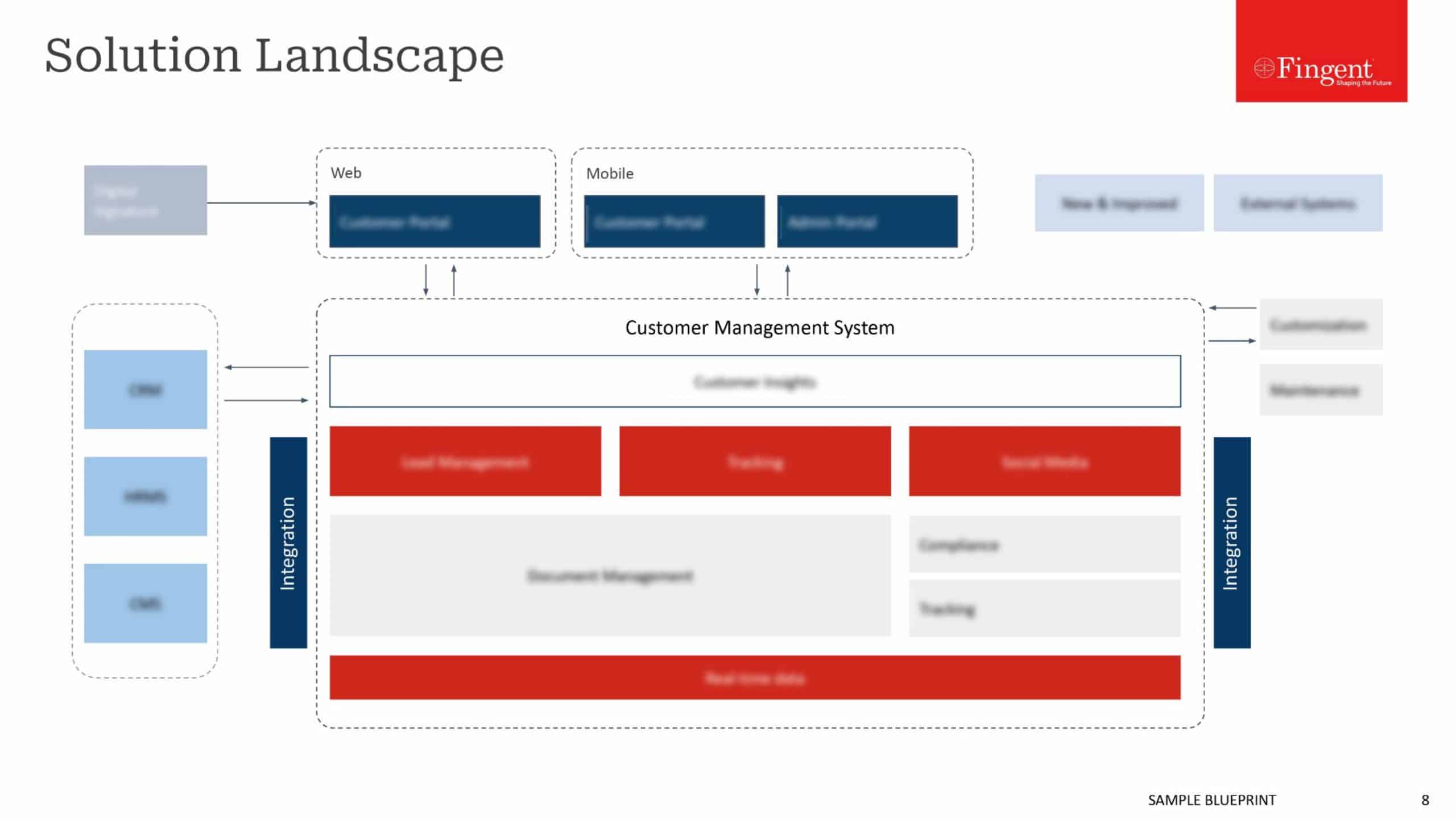
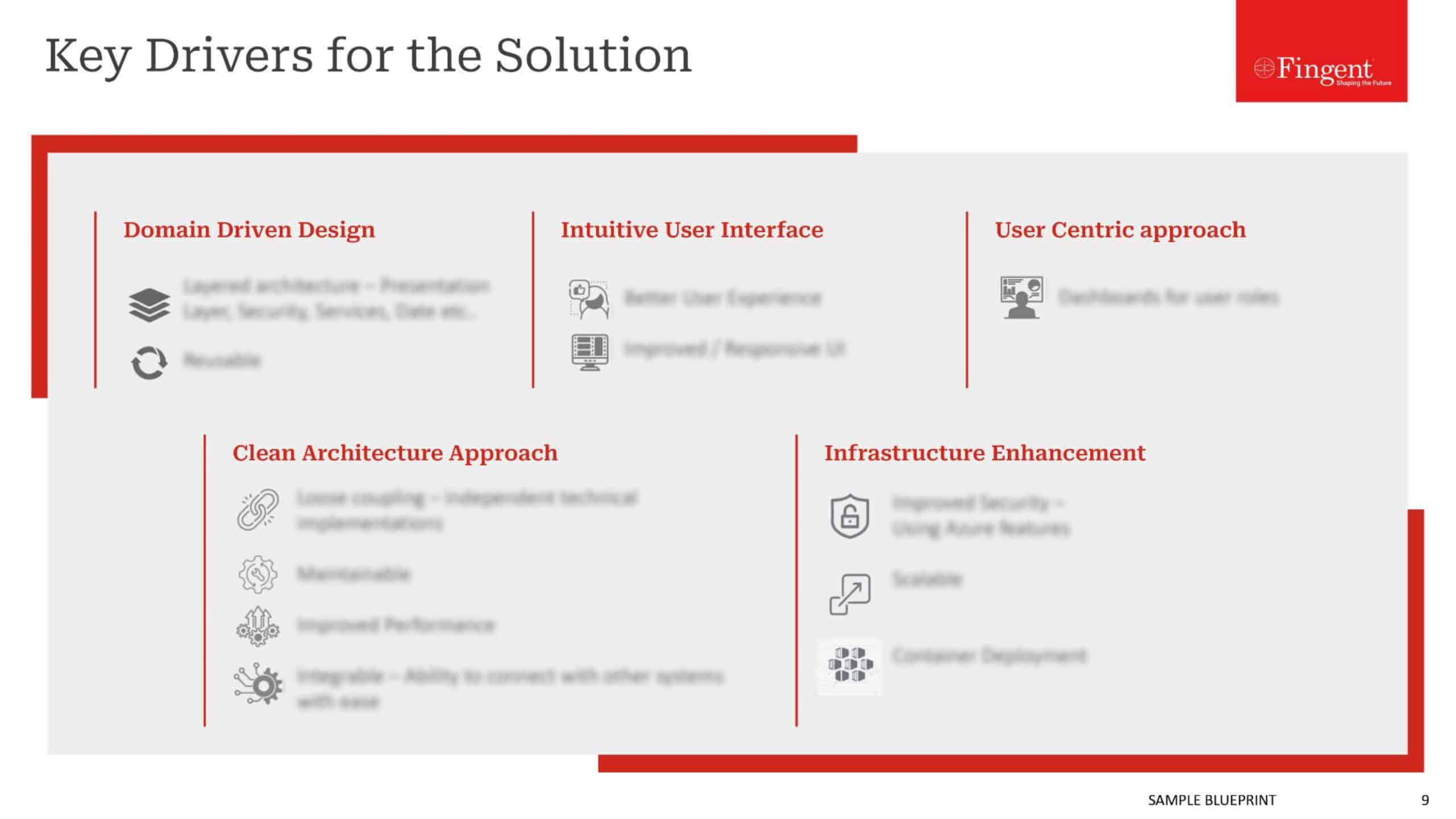
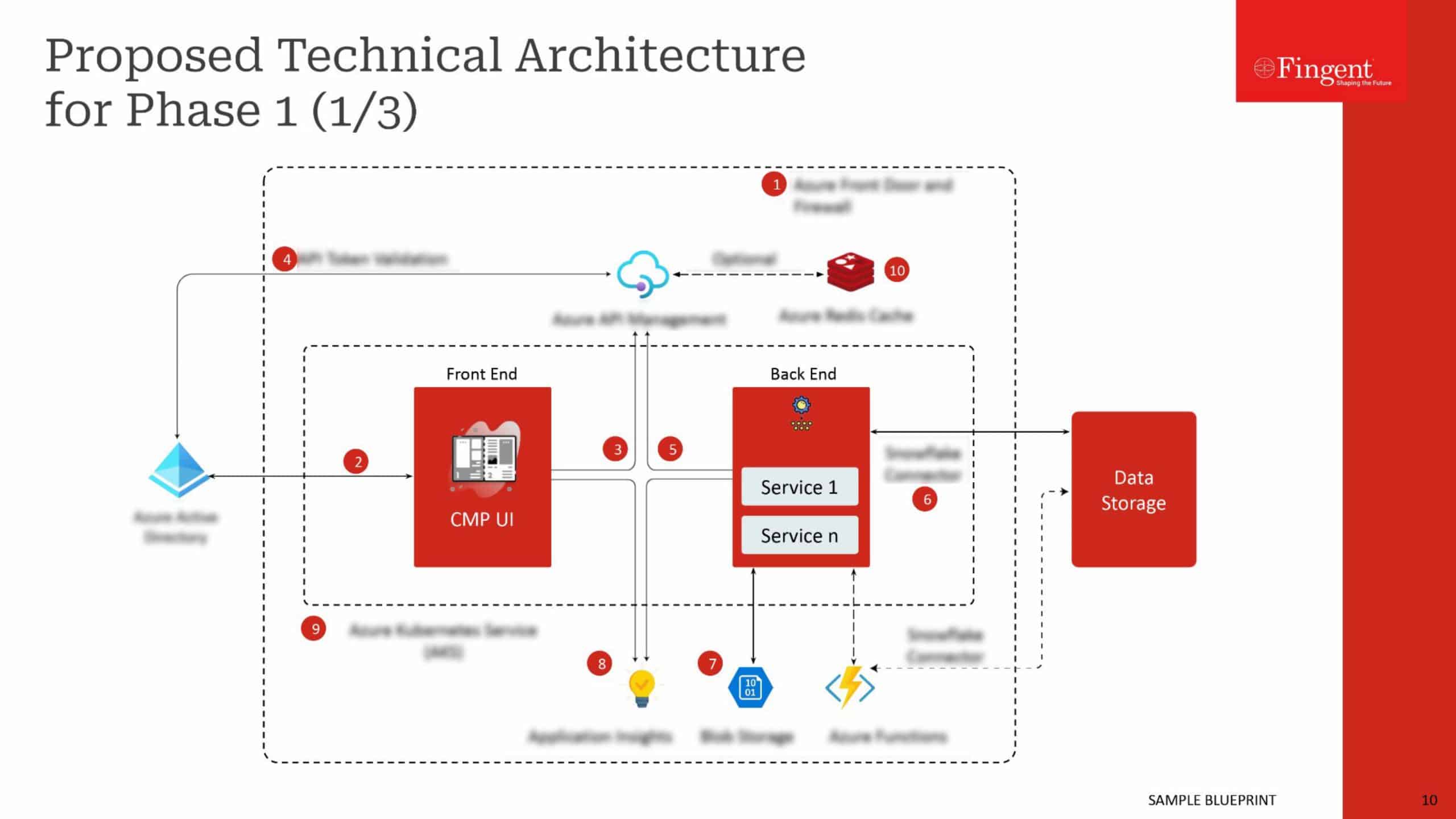
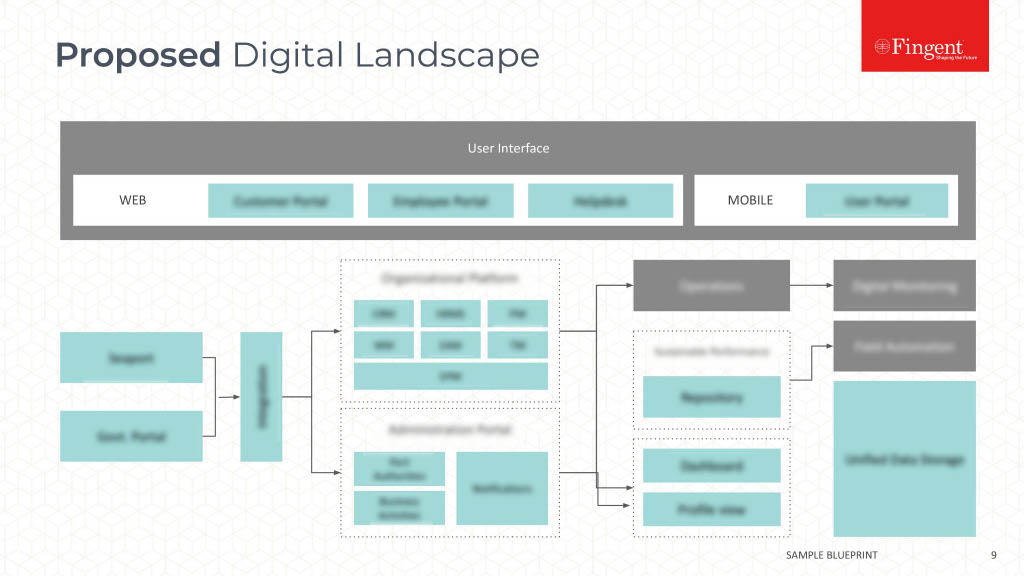
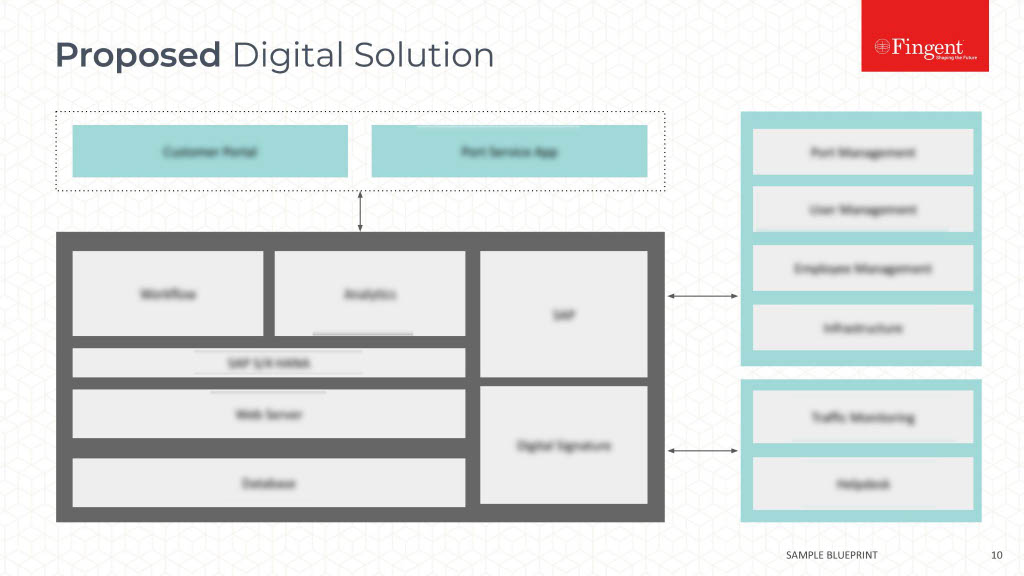
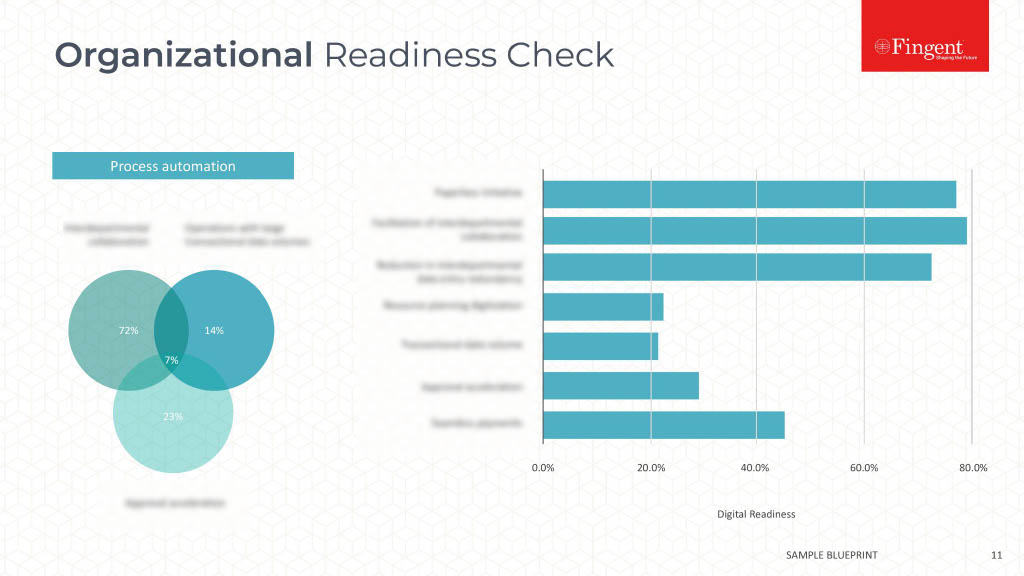
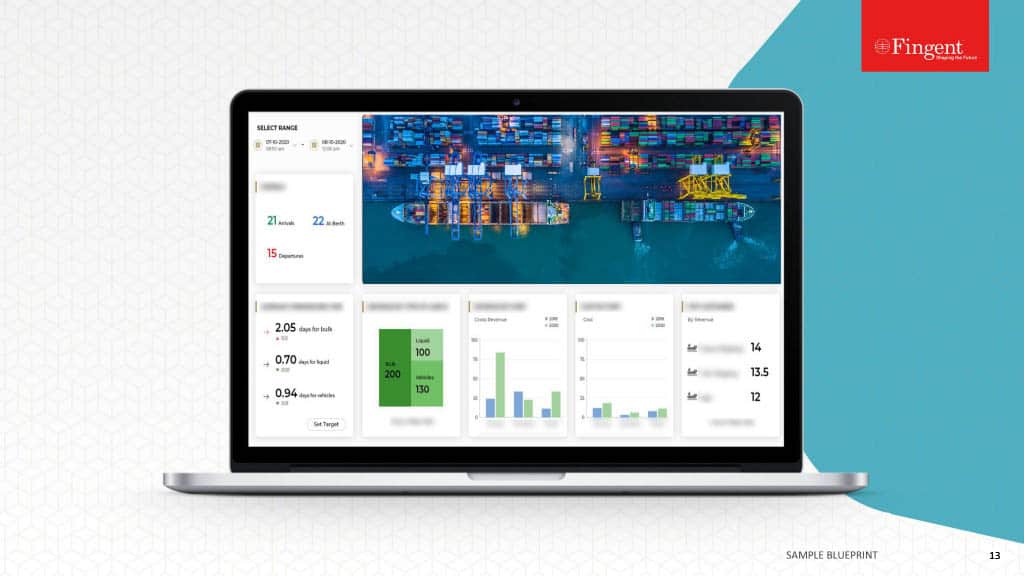
Tag: Machine learning algorithms
Machine learning is changing the face of everyday life, science, and business. It is revolutionizing all industries, from advancing medicine to powering various cutting-edge technologies. Though Machine learning (ML) was a part of AI’s evolution until the 1970s, it evolved independently. It has become a chief response tool for cloud computing and eCommerce.
The goal of machine learning in business is to adapt to new data independently and make decisions and recommendations based on thousands of analyses. Machine learning enables systems to learn, identify patterns and make informed decisions with minimal human intervention.
Today, ML is a necessary aspect of modern business. It uses algorithms and neural network models to improve the performance of computer systems. Machine learning in business and manufacturing is enabling organizations to achieve notable strides. These strides include increased performance and efficiencies, improved processes, and enhanced security.
This article will discuss the benefits of machine learning in business and its use cases.
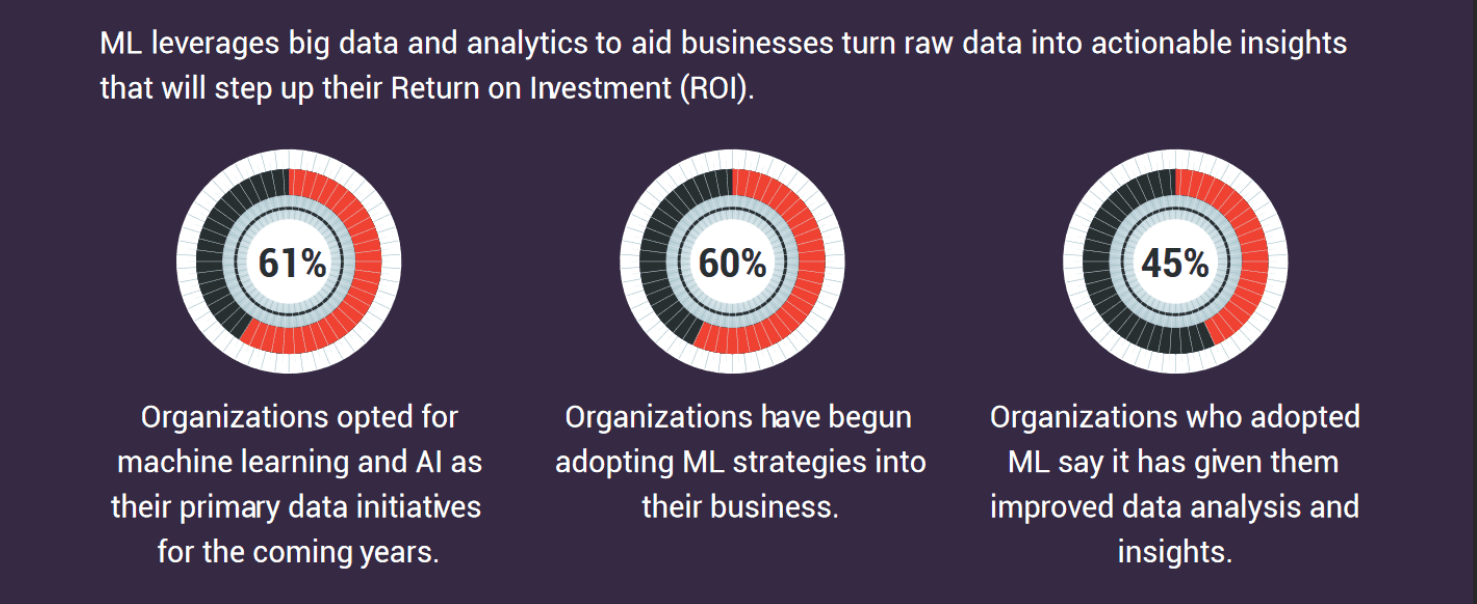
Remarkable Benefits of Machine Learning for Businesses
According to Fortune Business Insights, the global market size for machine learning in business is expected to grow to USD 209.91 billion by 2029, exhibiting a CAGR of 38.8% during the forecast period. ML has been and continues to scale operations tremendously. Across industries, ML has led to a boom in affordable data storage and faster and more reliable computational processing.
Here are six remarkable benefits of machine learning in business:
1. Automation for better decision-making
Most businesses find themselves wasting precious time sorting through duplicate and inaccurate data. Such businesses benefit from using the predictive modeling algorithms of ML in their processes. Such a process will understand duplicate inaccurate data and distinguish the anomalies. It enables the organization to avoid inaccurate reporting that can result in poor customer retention.
Instead, this will allow businesses to use their accurate database to detect wasted costs, missed opportunities for sales, and revenue capital. In addition, organizations can overcome challenges and risks that arise due to miscommunication or poor performance metrics. Thus, businesses can streamline their operations and improve decision-making which could be translated into better ROI.
2. Increased scalability with minimum expense
Semi-supervised machine learning algorithms can help organizations leverage useful insights from customer profiles and enable them to view their brands from customers’ perspectives. Doing so will equip organizations with relevant insights to build their brand by improving their products and services.
3. Predictive maintenance
Predictive maintenance that ML aids manufacturing firms’ power to follow best practices that lead to efficient and cost-effective operations. The historical and real-time data predict problems and stipulate strategies to solve those problems. Plus, workflow visualization tools can eliminate issues and unwanted expenses incurred due to those issues.
4. Financial analysis
ML can greatly assist as it gathers and analyzes large volumes of quantitative and accurate historical data. It is used for portfolio management, loan underwriting, fraud detection, and more.
5. Personalization
Using machine learning in business will allow organizations to know their customers better and provide them with a more personalized customer experience. Organizations no longer need to rely on guesswork because ML models can process different types of information collected from numerous sources and provide relevant data about their customers.
6. Cybersecurity
ML technologies can improve cybersecurity to solve cyberattacks once and for all. Empowered by ML, intelligent security programs can gather and process data about cyber threats and respond to them in real time. ML models can detect the slightest deviations in patterns and flag them. Or destroy an attack in its nascent stage.
Read more: Can Machine Learning Predict And Prevent Fraudsters?

Top Use Cases
Machine Language has made its mark across industries and found a place in many different applications. Here are some top use cases:
1. Enhanced social media features
Businesses can use machine learning algorithms to create attractive and effective social media features. For example, ML algorithms in Facebook enable it to identify and record a person’s activities. These activities include records of chats and the amount of time that person spends on each post. It uses this data to determine what kind of friends and topics may interest that person and accordingly make suggestions.
Read more: Why Time Series Forecasting Is A Crucial Part Of Machine Learning
2. Product recommendation
Product recommendation is an advanced application of machine learning techniques. It has been the most popular application of almost every eCommerce website today. This technique allows websites to track a consumer’s behavior based on their previous purchases, search patterns, and cart history. It enables the website to make apt product recommendations to that consumer.
3. Recognition
Image recognition is one of the most significant and notable ML and AI techniques. It is adopted further for pattern recognition, face detection, and face recognition.
4. Sentiment analysis
Sentiment analysis is a real-time ML application. It determines the emotion or opinion of the speaker or the writer. For example, a sentiment analyzer can detect the thought and tone of a written review or an email. It can analyze the review-based website, decision-making applications, and more.
5. Access control
Most large businesses are actively implementing ML models to determine the level of access an employee should be granted. This application of machine learning can ensure the security of the organization.
6. Bank Domain
Banks are using ML to prevent fraud and protect accounts from hackers. Machine learning algorithms determine what factors to consider in creating a filter to prevent an attack.
Read more: Machine Learning – Deciphering the most Disruptive Innovation
How Fingent Can Help with Deploying the Best of ML
Leveraging the capabilities of machine learning in business can open the door to many opportunities. It is wise for any organization to take advantage of ML rather than lag behind competitors. However, we understand if you have questions. That’s why Fingent software development experts are here to help you. We can deploy the best machine-learning models efficiently and smoothly.
As a partner, Fingent can work with your team as you take on digital initiatives for sustainable business growth. We enable our clients to make data-driven decisions by efficiently deploying machine learning in business. Our cost-effective services will save you a considerable amount of time and money.
Furthermore, we do not follow a one-size-fits-all strategy. We provide custom software development services that cater to your needs. Therefore, look no further if you are looking for a reliable, efficient IT partner to deploy the best machine-learning models.
Stay up to date on what's new

About the Author

Featured Blogs








Stay up to date on
what's new



Talk To Our Experts
Top 10 Algorithms to Create Functional Machine Learning Projects
From simple day-to-day functions to making computers smarter, Machine Learning algorithms help automate manual tasks for making our lives simpler. The significance of Machine Learning has grown even further, which is why enthusiastic data scientists and engineers look forward to learning different techniques to hone their skills.
Below are the top 10 Machine Learning algorithms that you should know. These will help you to create practical projects, no matter whether you choose Supervised, Unsupervised, or Reinforcement Machine Learning model.
Read our Infographic: What Machine Learning is and why it is important in business
1. Apriori Algorithm
Apriori algorithm is a type of machine learning algorithm, which creates association rules based on a pre-defined dataset. The rules are in the IF_THEN format, which means that if action A happens, then action B will likely occur as well. The algorithm derives such conclusions by analyzing the ratio of action B to action A.
One of the most common examples of the Apriori algorithm can be seen in Google auto-complete. When you type a word, the algorithm automatically suggests associated words that are mostly typed with that.
2. Naive Bayes Classifier Algorithm
Naive Bayes Classifier algorithm works by presuming that any specific property in a category is not related to the other properties of the group. This helps the algorithm to consider all the features independently as it calculates the outcome. It is very easy to create a Naive Bayes model for huge datasets, and can even do better than many of the complex classification methods.
The best example of the Naive Bayes Classifier algorithm will be email spam filtering. The function automatically classifies different emails as spam or not spam.
3. Linear Regression Algorithm
Linear Regression algorithm determines the correlation between a dependent variable and an independent variable. It helps understand the effect that the independent variable will cause on the dependent variable if the former’s value is changed. The independent variable is also referred to as the explanatory variable, while the dependent variable is termed as the factor of interest.
Generally, the Linear Regression algorithm is used in risk assessment processes, especially in the insurance industry. The model can help to figure out the number of claims as per different age groups and then calculate the risk as per the age of the customer.
Related Reading: Can Machine Learning Predict And Prevent Fraudsters?
4. K-Means Algorithm
K-Means algorithm is commonly used for solving clustering problems. It takes datasets into a specific number of clusters, which is referred to as “K”. The data is categorized in such a way that all the data points in the cluster remain homogenous. At the same time, the data points in one cluster will be different from the data grouped in other clusters.
For instance, when you look for, say, “date”, on the search engine, it could mean a fruit, a particular day, or a romantic night out. The K-Means algorithm groups all the web pages that mention each of the different meanings to give you the best results.
5. Decision Tree Algorithm
Decision Tree algorithm is the most popular Machine Learning algorithms out there today. The model works by classifying problems for both categorical as well as continuous dependent variables. Here, all the possible outcomes are divided into different standardized sets with the most significant independent variables using a tree-branching methodology.
The most common example of the Decision Tree algorithm can be seen in the banking industry. The system helps financial institutions to categorize loan applicants as well as determine the probability of a customer defaulting on his/her loan payments.
Related Reading: How Predictive Algorithms and AI Will Rule Financial Services
6. Support Vector Machine Algorithm
Support Vector Machine algorithm is used to classify data as points in a vast n-dimensional plane. Here, “n” refers to the number of properties in hand, each of which is linked to a specific subset to categorize the data. A common use of the Support Vector Machine algorithm can be seen in the regression of problems. It works by categorizing data into different levels using a particular line or hyper-plane.
For instance, stockbrokers use the Support Vector Machine algorithm to compare the performance of different stocks and listings. This helps them to device the best decisions for investing in the most lucrative stocks and options.
7. Logistic Regression Algorithm
Logistic Regression algorithm helps calculate separate binary values from a cluster of independent variables. It then helps to forecast the likelihood of an outcome by analyzing the data against a logit function. Including interaction terms, eliminating properties, standardizing techniques, and using a non-linear model can also be used to create better logistic regression models.
The probability of the outcome of a specific event in the Logistic Regression algorithm is calculated as per the included variables. It is commonly seen in politics to predict if a candidate will win or lose in the election.
8. K- Nearest Neighbors Algorithm
K Nearest Neighbors or KNN algorithm is used for both the classification as well as regression of different problems. The model saves the data available from several cases, which is referred to as K, and classifies new cases as per the data from the K neighbors based on distance function. The new case is then included in the identified dataset.
K Nearest Neighbors needs a lot of storage space to save all the data from different variables. However, it only functions when needed and can be very reliable in predicting the outcome of an event.
9. Random Forest Algorithm
Random Forest algorithm works by grouping different decision trees based on their attributes. This model can deal with some of the common limitations of the Decision Tree algorithm. It can also be more accurate to predict the outcome when the number of decisions goes higher. The decision trees are mapped here based on the CART or Classification and Regression Trees model.
A common example of the Random Forest algorithm can be seen in the automobile industry. It is seen to be very productive in forecasting the breakdown of a specific automobile part.
10. Gradient Boosting and Adaptive Boosting
Gradient Boosting and Adaptive Boosting (AdaBoost) algorithms can be used when you need to handle a huge amount of data and predict the outcome with the highest accuracy possible. Boosting algorithms combine the power of different basic learning algorithms to improve the results. It can also merge weak or average predictors to get a strong estimator model.
Gradient boosting is generally used with decision trees, while AdaBoost is typically used to improve binary classification problems. Boosting can also correct the misclassifications found in different base algorithms.
The above-listed Machine Learning algorithms will help you get started with your desired projects right away. These will equip you for understanding the scope of Machine Learning as well as work out complex problems more easily.
Related Reading: How Machine Learning Boosts Customer Experience
Want to develop machine learning applications that deliver better experiences for your users? Connect with us.
Stay up to date on what's new
About the Author

Featured Blogs
Stay up to date on
what's new