Top 10 Must-Know Machine Learning Algorithms in 2024
Top 10 Algorithms to Create Functional Machine Learning Projects
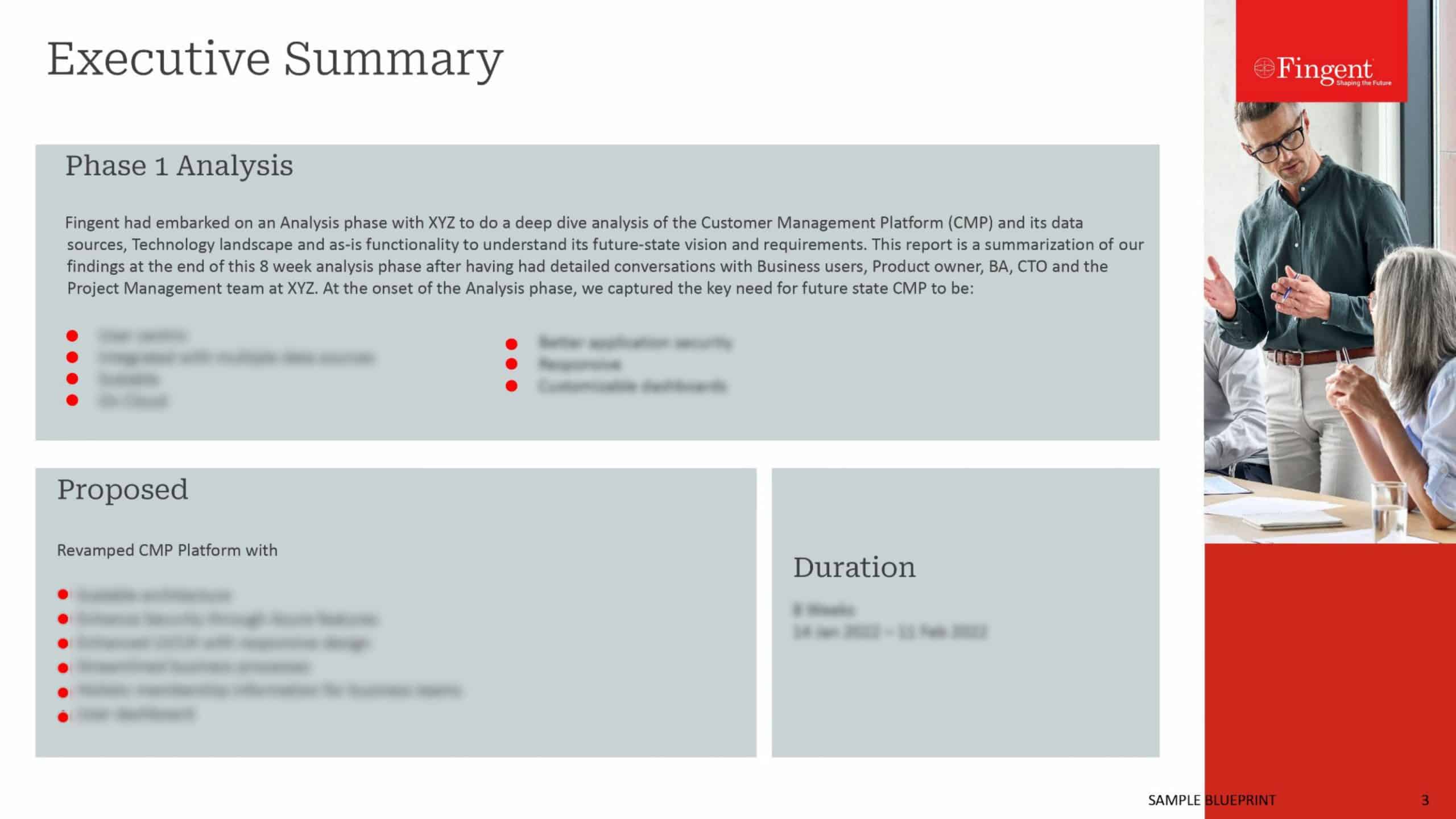
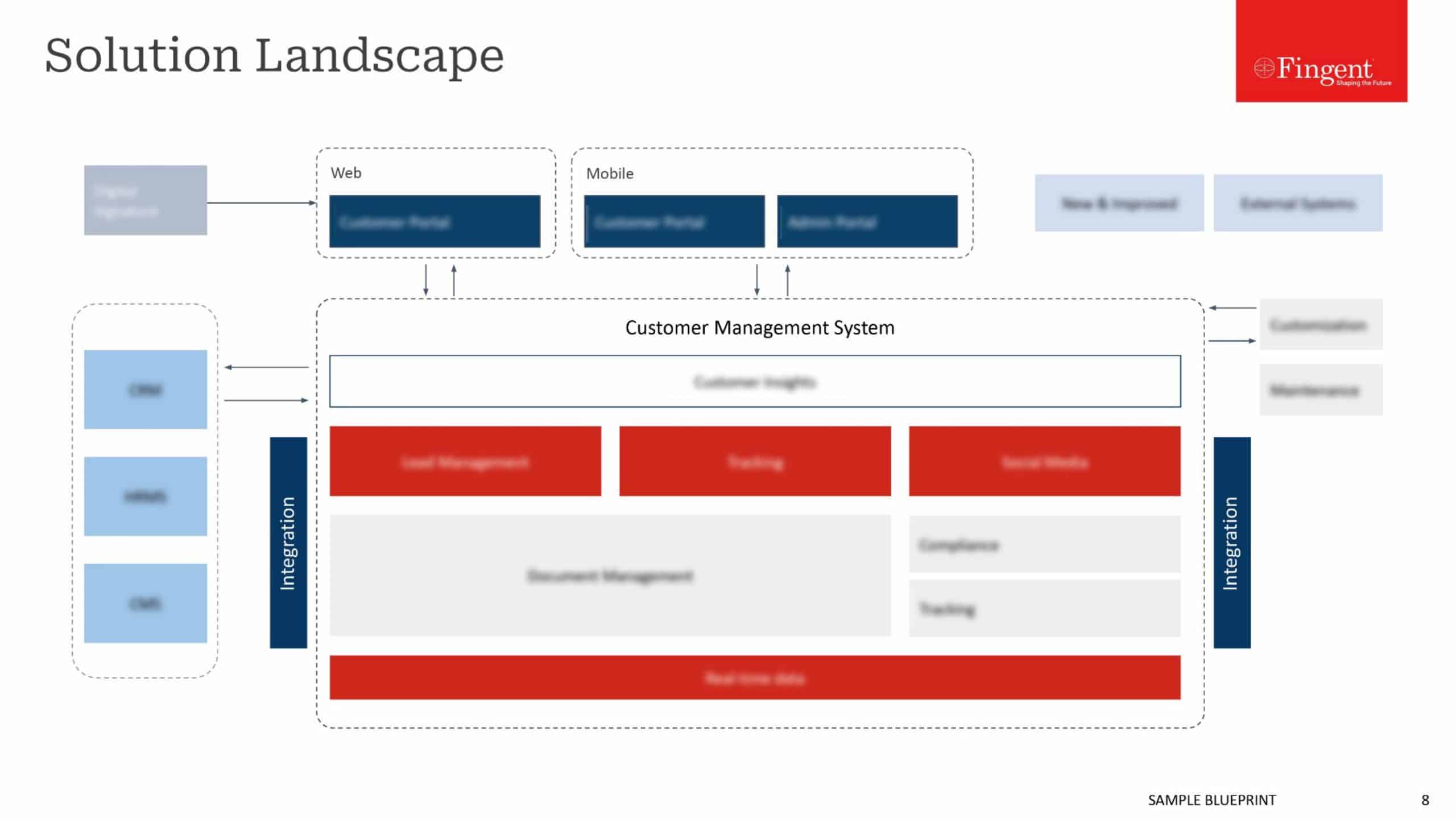
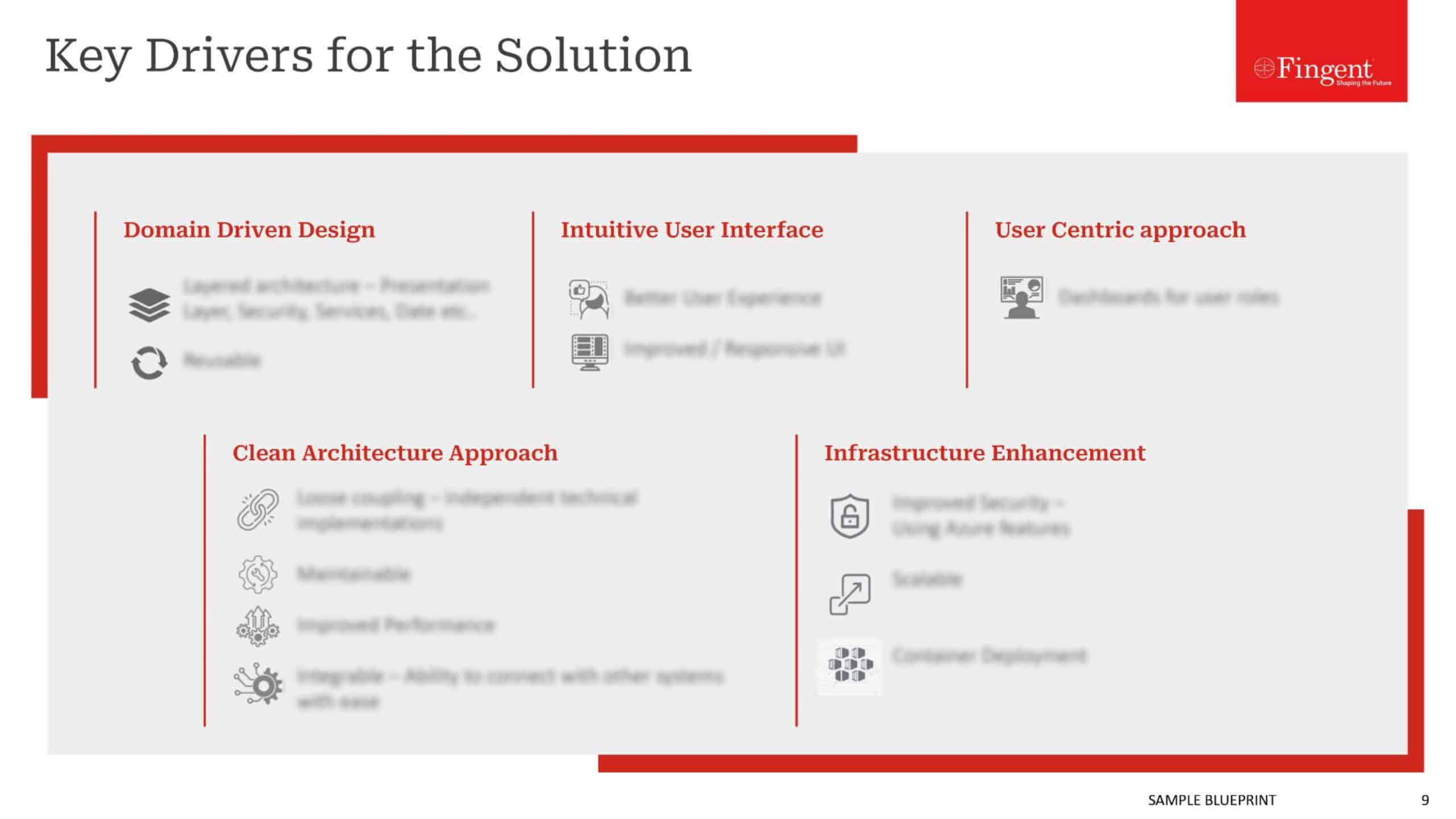
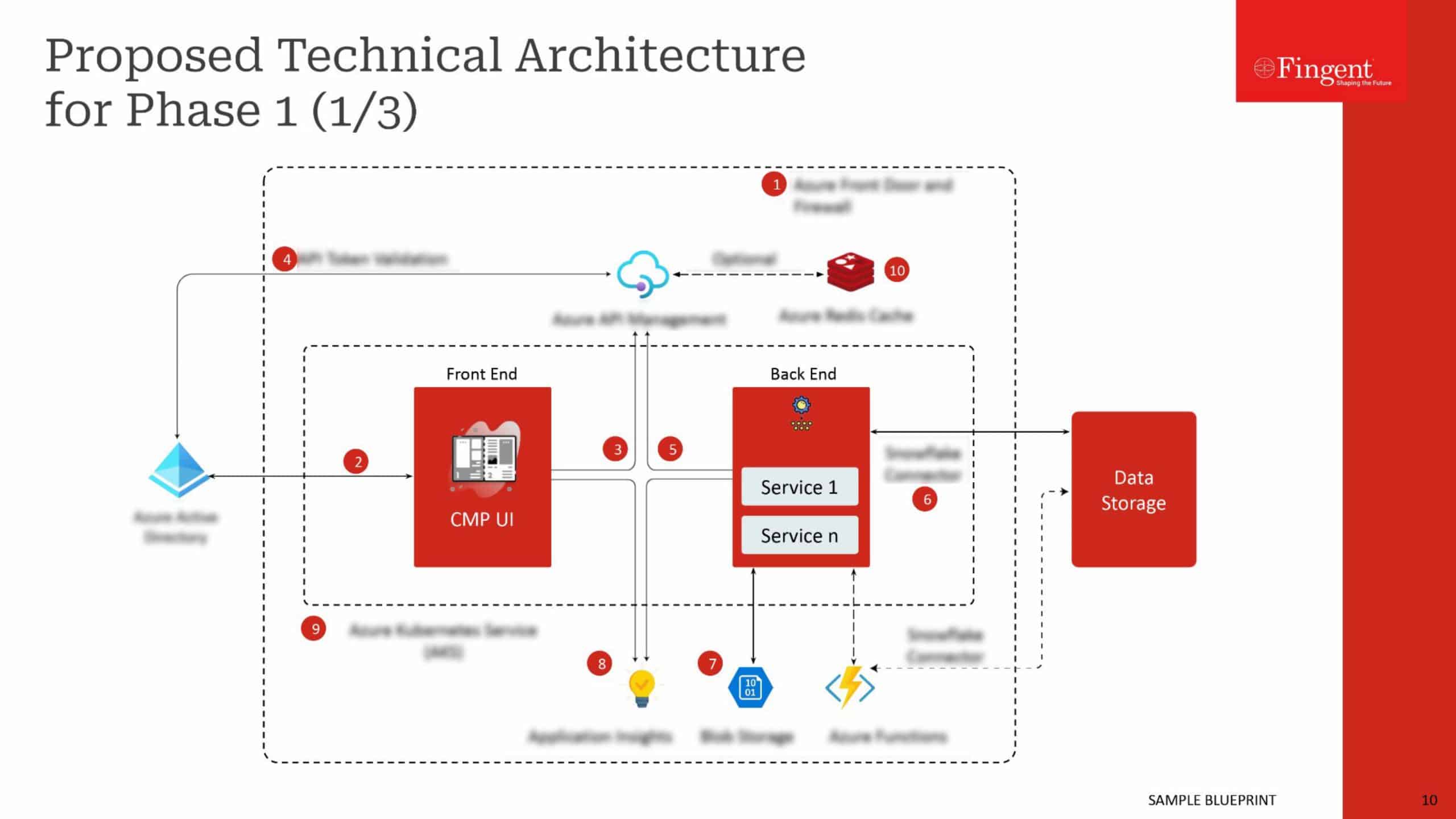
From simple day-to-day functions to making computers smarter, Machine Learning algorithms help automate manual tasks for making our lives simpler. The significance of Machine Learning has grown even further, which is why enthusiastic data scientists and engineers look forward to learning different techniques to hone their skills.
Below are the top 10 Machine Learning algorithms that you should know. These will help you to create practical projects, no matter whether you choose Supervised, Unsupervised, or Reinforcement Machine Learning model.
Read our Infographic: What Machine Learning is and why it is important in business
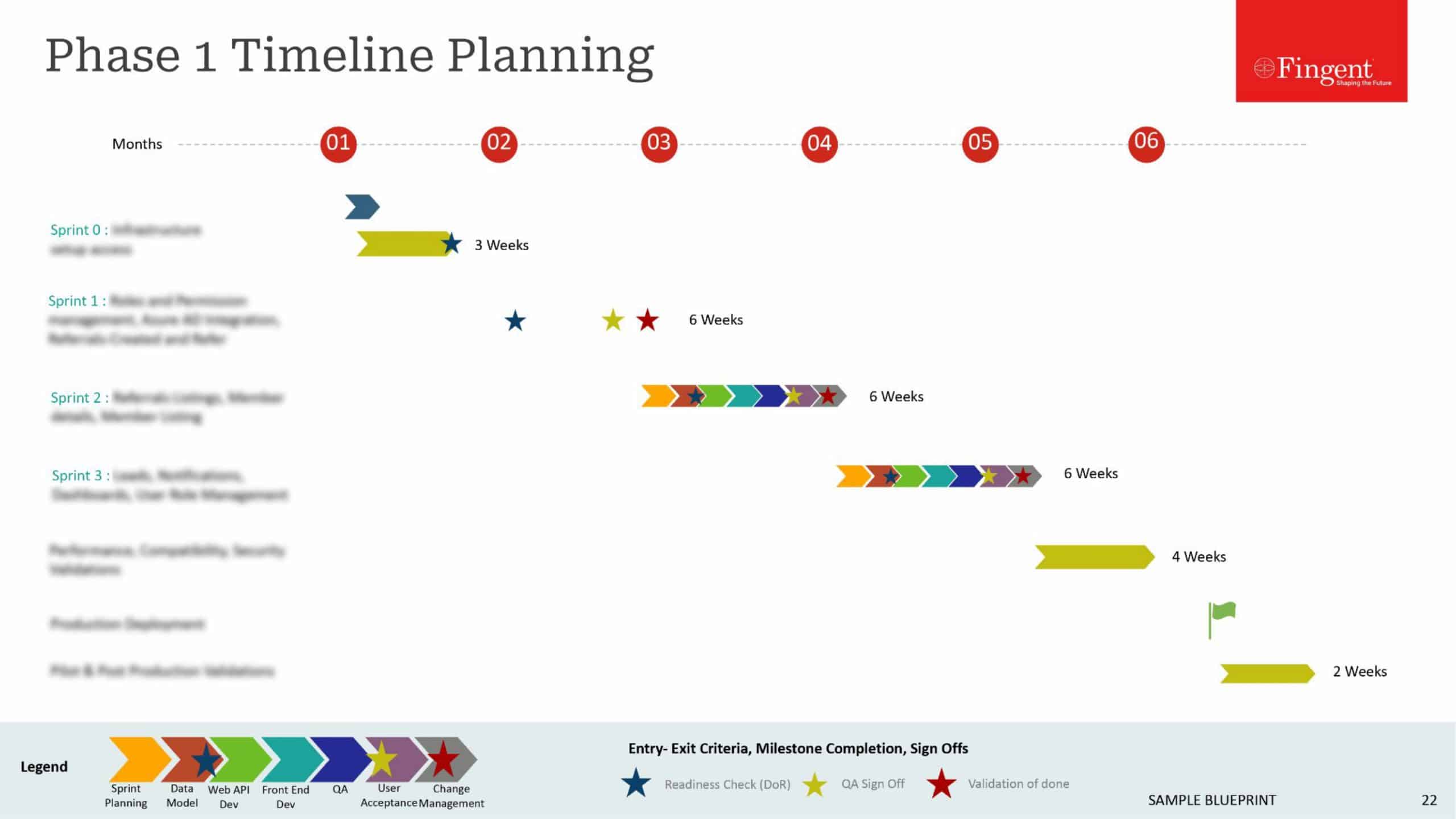
1. Apriori Algorithm
Apriori algorithm is a type of machine learning algorithm, which creates association rules based on a pre-defined dataset. The rules are in the IF_THEN format, which means that if action A happens, then action B will likely occur as well. The algorithm derives such conclusions by analyzing the ratio of action B to action A.
One of the most common examples of the Apriori algorithm can be seen in Google auto-complete. When you type a word, the algorithm automatically suggests associated words that are mostly typed with that.
2. Naive Bayes Classifier Algorithm
Naive Bayes Classifier algorithm works by presuming that any specific property in a category is not related to the other properties of the group. This helps the algorithm to consider all the features independently as it calculates the outcome. It is very easy to create a Naive Bayes model for huge datasets, and can even do better than many of the complex classification methods.
The best example of the Naive Bayes Classifier algorithm will be email spam filtering. The function automatically classifies different emails as spam or not spam.
3. Linear Regression Algorithm
Linear Regression algorithm determines the correlation between a dependent variable and an independent variable. It helps understand the effect that the independent variable will cause on the dependent variable if the former’s value is changed. The independent variable is also referred to as the explanatory variable, while the dependent variable is termed as the factor of interest.
Generally, the Linear Regression algorithm is used in risk assessment processes, especially in the insurance industry. The model can help to figure out the number of claims as per different age groups and then calculate the risk as per the age of the customer.
Related Reading: Can Machine Learning Predict And Prevent Fraudsters?
4. K-Means Algorithm
K-Means algorithm is commonly used for solving clustering problems. It takes datasets into a specific number of clusters, which is referred to as “K”. The data is categorized in such a way that all the data points in the cluster remain homogenous. At the same time, the data points in one cluster will be different from the data grouped in other clusters.
For instance, when you look for, say, “date”, on the search engine, it could mean a fruit, a particular day, or a romantic night out. The K-Means algorithm groups all the web pages that mention each of the different meanings to give you the best results.
5. Decision Tree Algorithm
Decision Tree algorithm is the most popular Machine Learning algorithms out there today. The model works by classifying problems for both categorical as well as continuous dependent variables. Here, all the possible outcomes are divided into different standardized sets with the most significant independent variables using a tree-branching methodology.
The most common example of the Decision Tree algorithm can be seen in the banking industry. The system helps financial institutions to categorize loan applicants as well as determine the probability of a customer defaulting on his/her loan payments.
Related Reading: How Predictive Algorithms and AI Will Rule Financial Services
6. Support Vector Machine Algorithm
Support Vector Machine algorithm is used to classify data as points in a vast n-dimensional plane. Here, “n” refers to the number of properties in hand, each of which is linked to a specific subset to categorize the data. A common use of the Support Vector Machine algorithm can be seen in the regression of problems. It works by categorizing data into different levels using a particular line or hyper-plane.
For instance, stockbrokers use the Support Vector Machine algorithm to compare the performance of different stocks and listings. This helps them to device the best decisions for investing in the most lucrative stocks and options.
7. Logistic Regression Algorithm
Logistic Regression algorithm helps calculate separate binary values from a cluster of independent variables. It then helps to forecast the likelihood of an outcome by analyzing the data against a logit function. Including interaction terms, eliminating properties, standardizing techniques, and using a non-linear model can also be used to create better logistic regression models.
The probability of the outcome of a specific event in the Logistic Regression algorithm is calculated as per the included variables. It is commonly seen in politics to predict if a candidate will win or lose in the election.
8. K- Nearest Neighbors Algorithm
K Nearest Neighbors or KNN algorithm is used for both the classification as well as regression of different problems. The model saves the data available from several cases, which is referred to as K, and classifies new cases as per the data from the K neighbors based on distance function. The new case is then included in the identified dataset.
K Nearest Neighbors needs a lot of storage space to save all the data from different variables. However, it only functions when needed and can be very reliable in predicting the outcome of an event.
9. Random Forest Algorithm
Random Forest algorithm works by grouping different decision trees based on their attributes. This model can deal with some of the common limitations of the Decision Tree algorithm. It can also be more accurate to predict the outcome when the number of decisions goes higher. The decision trees are mapped here based on the CART or Classification and Regression Trees model.
A common example of the Random Forest algorithm can be seen in the automobile industry. It is seen to be very productive in forecasting the breakdown of a specific automobile part.
10. Gradient Boosting and Adaptive Boosting
Gradient Boosting and Adaptive Boosting (AdaBoost) algorithms can be used when you need to handle a huge amount of data and predict the outcome with the highest accuracy possible. Boosting algorithms combine the power of different basic learning algorithms to improve the results. It can also merge weak or average predictors to get a strong estimator model.
Gradient boosting is generally used with decision trees, while AdaBoost is typically used to improve binary classification problems. Boosting can also correct the misclassifications found in different base algorithms.
The above-listed Machine Learning algorithms will help you get started with your desired projects right away. These will equip you for understanding the scope of Machine Learning as well as work out complex problems more easily.
Related Reading: How Machine Learning Boosts Customer Experience
Want to develop machine learning applications that deliver better experiences for your users? Connect with us.
Stay up to date on what's new

About the Author

Recommended Posts

30 Jul 2023 B2B
SAP Customer Experience: Creating Seamless Omni-Channel Experiences
Businesses find themselves at a critical juncture as customer expectations soar and their loyalty hangs by a thread. The key to captivating and retaining customers lies in mastering the art……

25 Jul 2023 B2B
A Quick Guide To A Successful Digital Transformation Journey!
Today, technology seamlessly weaves its way into every aspect of our daily lives. That's precisely what digital transformation is all about - a process that enables businesses to harness the……

11 May 2023 B2B
Boosting Customer Experience: The Power of AI in Customer Experience
“A simple rule: always give people more than they expect.” - Nelson Boswell The cycle of business starts and ends with customers. Keeping them satisfied and happy is the……

10 Mar 2023 B2B
Looking Ahead: The Future of Work in the Automotive Industry!
The automobile industry is one of the largest sectors in the world. In just the U.S., the car & automobile manufacturing industry boasts a market size of $104.1 billion. However,……
Featured Blogs








Stay up to date on
what's new