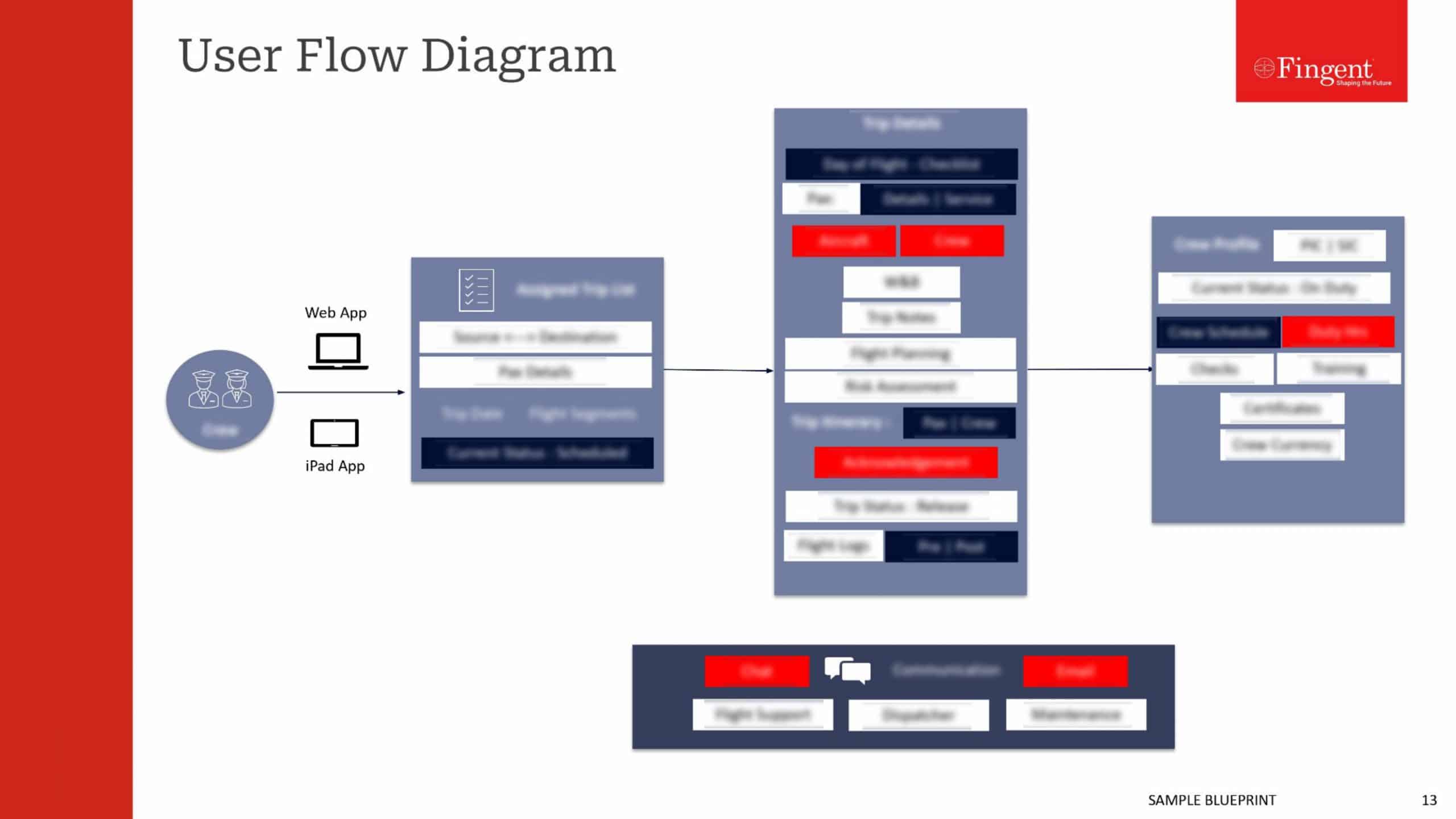
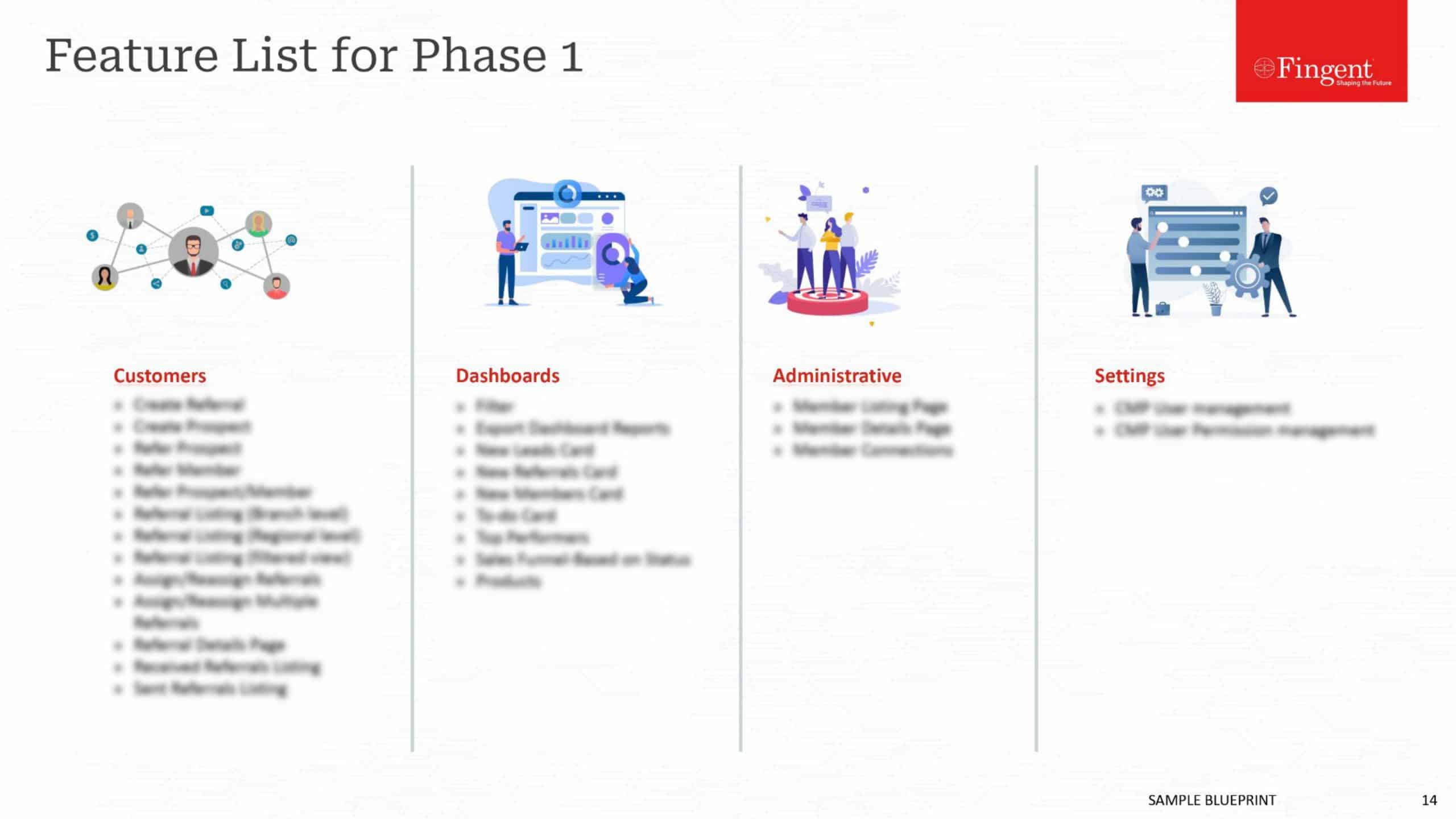
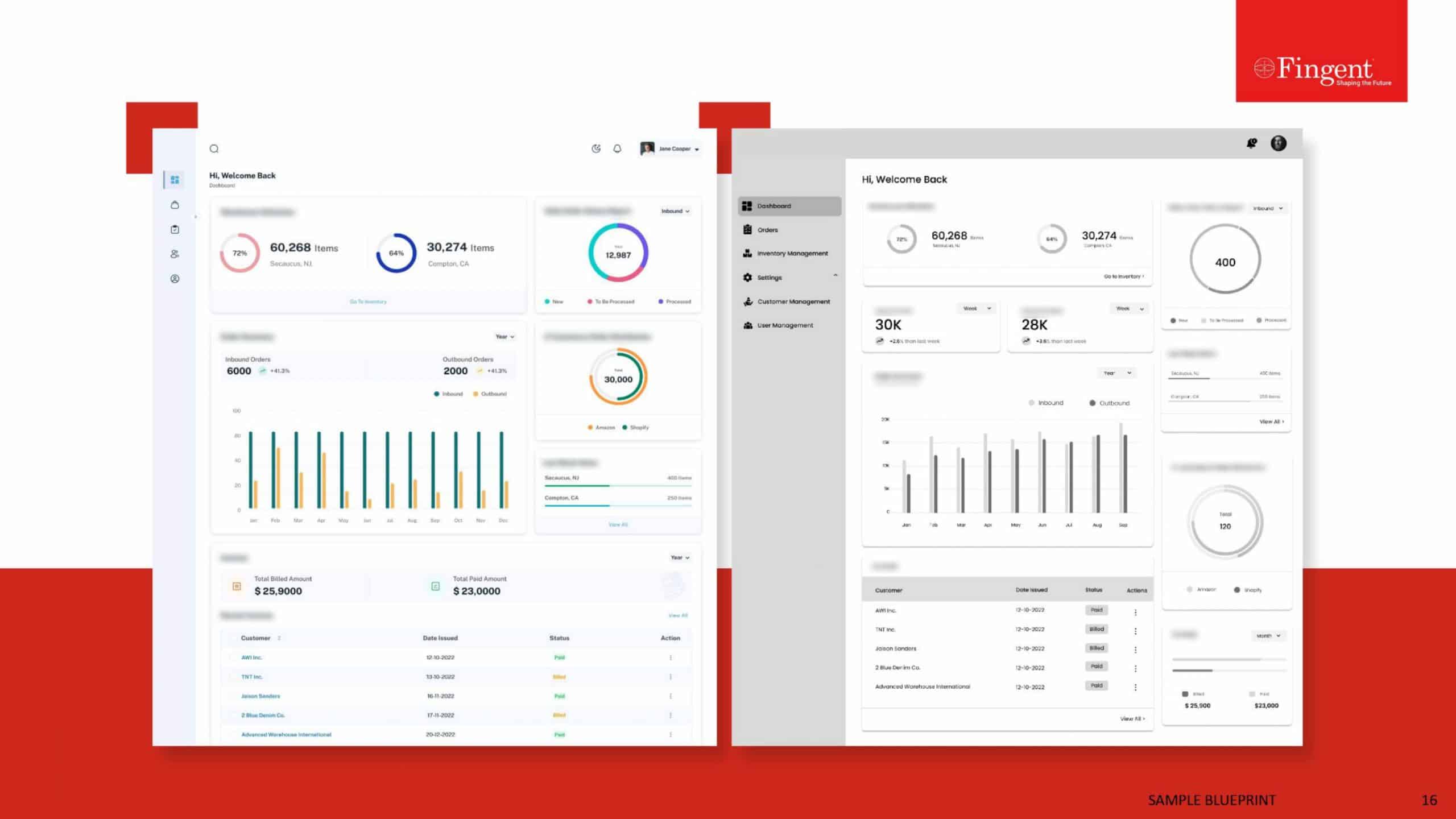
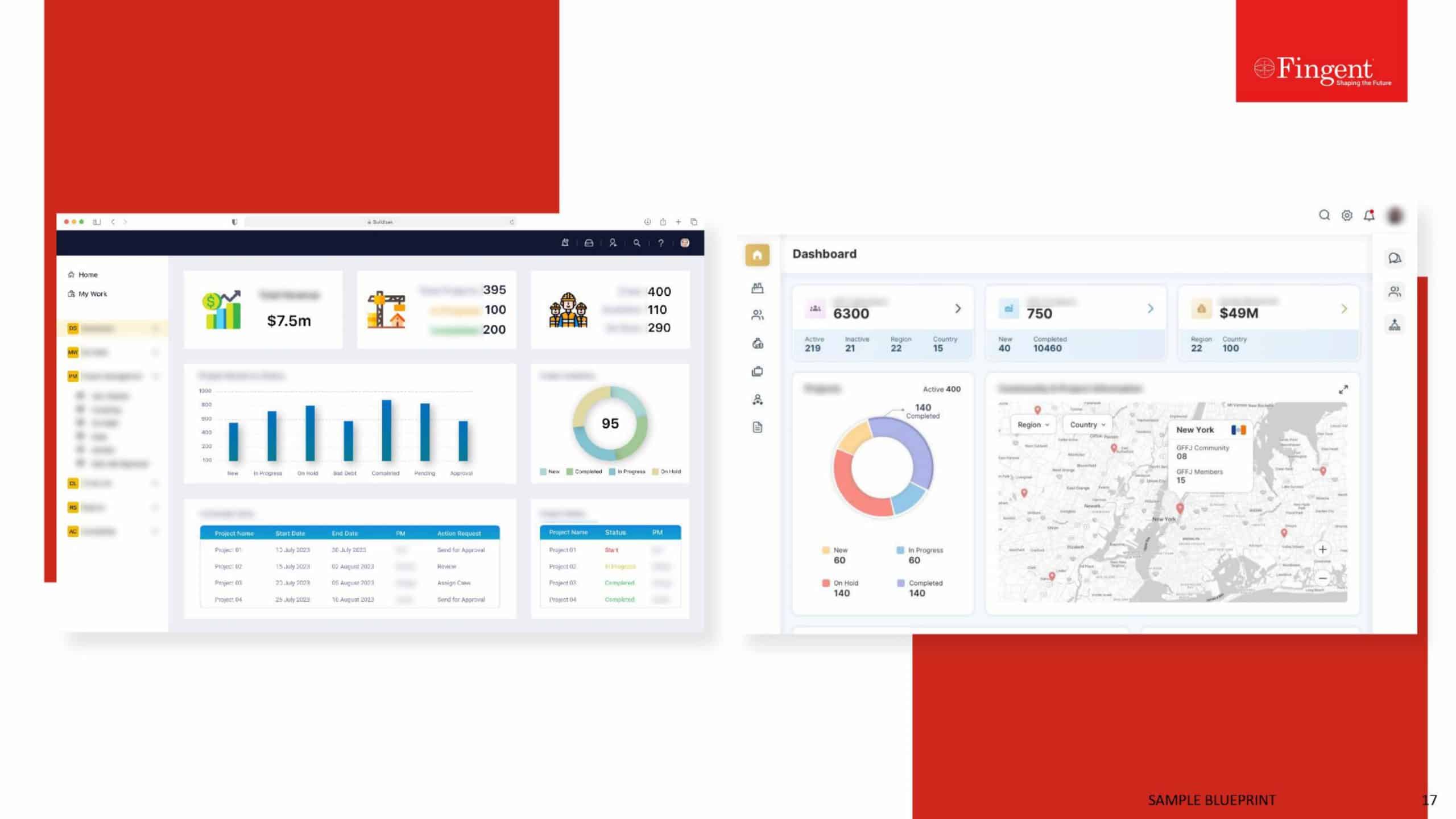
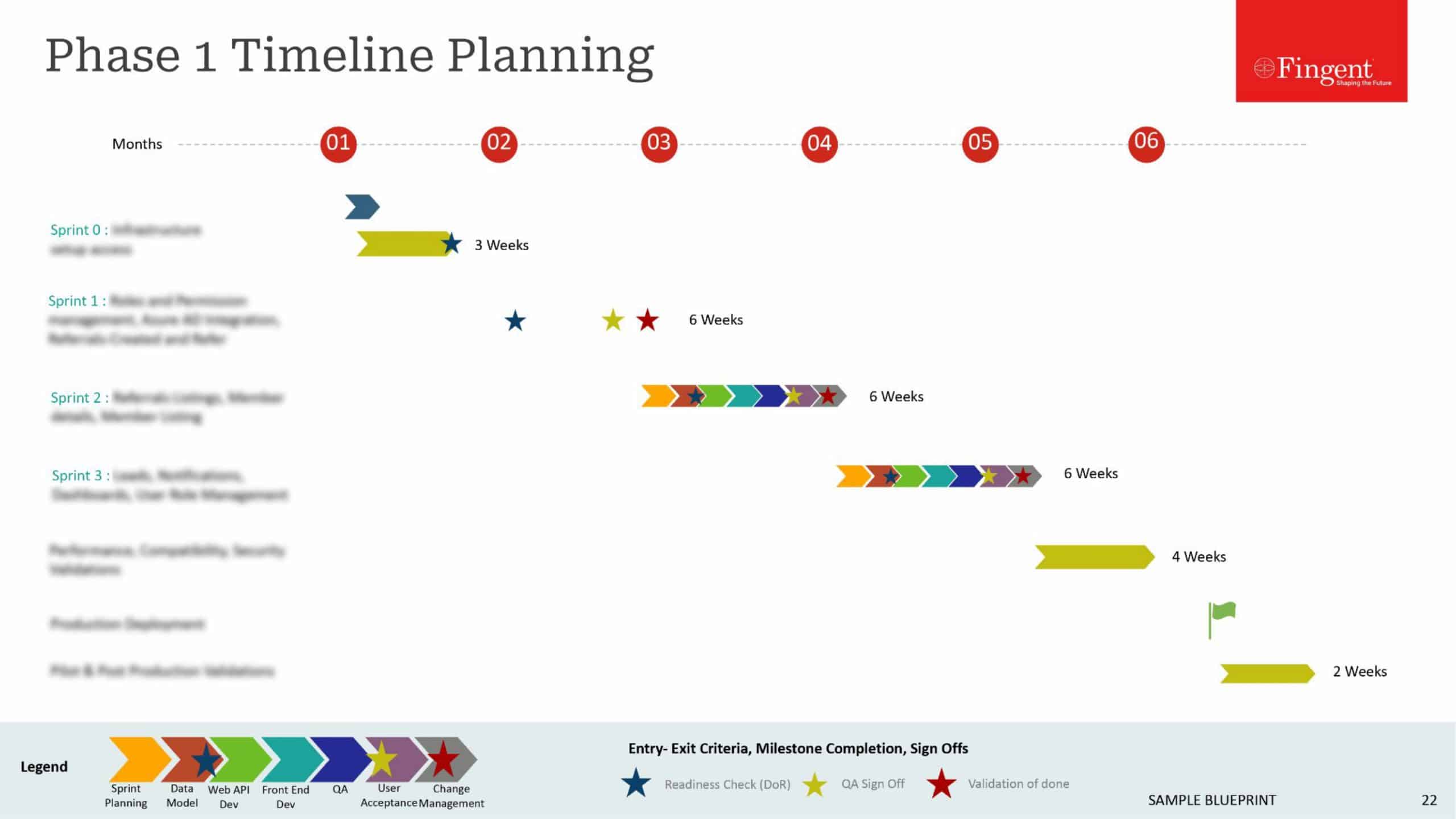
Tag: data processing
Undoubtedly, data is what we see almost everywhere, and it is enormous. And it doesn’t stop there, it is growing continuously at a level beyond imagination! Let’s have a look at how it has changed over the years.
A look into how Data and AI transformed in years!
In the 1950s, when there were fewer technological developments, companies would collect the data(offline) and analyze it manually. This was also backed by limited data sources that made it time-consuming in obtaining the results.
The mid-2000s paved the way for changing the world for the better and it was during this time the term “big data” was coined. Almost every business that had something to do with digital infrastructure started looking for ways to use the large data and come up with meaningful insights.
This era also saw the invention of tools like Data mining, OLAP, etc., taking technological advancements to the next level. In general, the internet gained immense popularity not only for organizations but also for households. During this time, technology became more advanced and provided automated options for managing data, and data analysts could analyze data, trends, etc., and provide better recommendations.
Google, Amazon, Paypal, and others also made a mark causing the volume of data to reach newer heights. However, all this posed a storage and processing problem.
The late 2000s to early 2010s saw a surge in Facebook, Twitter, Smartphones, and connected devices. The companies used improved search algorithms, recommendations, and suggestions driven by the analytics rooted in the data to attract their customers. Enterprises also realized that would have to deal with unstructured data and so they got familiar with databases such as NoSQL. New Technologies were introduced for faster data processing and machine learning models were used for advanced analytics.
Now, businesses are a step ahead and using automated tools using cloud and big data technologies. With cloud platforms, it is now easier to enable massive streaming and complex analytics.
Read more: 5 ways in which big data can add value to your custom software development

Having seen how data has evolved over the years, let’s have a look at how Artificial Intelligence has transformed in the last generation.
In 1950, a British mathematician and WWII code-breaker- Alan Turing was one of the first people to come up with the idea of machines that could think. To date, the Turing Test is used as a benchmark to determine a machine’s ability to think like a human. While this notion was ridiculed at the time, the term artificial intelligence gained popularity in the mid-1950s, after Turing’s death.
Later, Marvin Minsky, an American cognitive scientist picked up the AI torch and co-founded the Massachusetts Institute of Technology’s AI laboratory in 1959. He was one of the leading thinkers in the AI field through the 1960s and 1970s. It was the rise of personal computers in the 1980s that sparked interest in machines that think.
That said, it took several decades for people to recognize the true power of AI. Today, Investors and physicists like Elon Musk and Stephen Hawking are continuing the conversation about the potential for AI technology in combination with big data could have and how it could change human history.
AI technology’s promising feature is its ability to continually learn from the data it collects. The more the data it collects and analyses through specially designed algorithms, the better the machine becomes at making predictions.
Impact on business
AI and big data have an impact on businesses like never before. Whether it is workflow management tools, trend predictions, or even advertising, AI has changed the way we do business. Recently, a Japanese venture capital firm became the first company ever to nominate an AI board member for its ability to predict market trends faster than humans.
On the other hand, data has been the primary driver for AI advancements. Machine learning technologies can collect and organize a large amount of data to make predictions and insights that otherwise cannot be achieved with manual processing. This not only increases organizational efficiency but reduces the chances of any critical mistake. AI can detect spam filtering or payment fraud and alert you in real-time about malicious activities.
AI machines can be trained to handle incoming customer support calls thereby reducing costs. Additionally, you can use these machines to optimize the sales funnel by scanning the database and searching the Web for prospects that have similar buying patterns as your current customers.
Read more: The Future of Artificial Intelligence – A Game Changer for Industries

5 trends in data and artificial intelligence that can help data leaders.
1. Customer experience will be the key
Supply chain and operating costs will mean nothing if you are unable to hold on to your customers. Today, businesses have to be more connected with their customers to be on top of the game. From in-person and digital sales to call centers, companies will have to collect data to have a holistic view of the customer. Businesses must consider other forms of interaction such as using voice analytics to understand how customers interact with call centers or chatbots.
2. Leveraging External data
External data can provide early warning signs about what’s going on. To make external data work, companies must start with a business problem and then think about the possible data that could be used to solve it. That said, companies might need to modernize data flows to leverage external data.
While many businesses have started leveraging external data, some companies haven’t leveraged it yet as they are either too focused on internal data or finding it difficult to transfer data.
A prime example of brands that used external data is Hershey’s Chocolates. It leveraged external data to predict an increase in the number of people using chocolate bars for Backyard S’mores and a decline in sales for smaller candy bars for trick-or-treating.
3. CDOs leading the way towards a data-driven culture
Introducing any new technology without training your employees to adapt and figure out new skills and processes will not be effective. According to Cindi Howson, chief data strategy officer at analytics platform provider ThoughtSpot, Chief Data Officers (CDOs) need to take the lead and empower their employees and the organization to gain time and efficiency with data. Also, CDOs will have to make sure to upskill employees to take full advantage of new technology.
4. Multi-Modal learning
With advances in technology, AI can support multiple modalities such as text, vision, speech, and IoT sensor data. All this is helping developers find innovative ways to combine modalities to improve common tasks such as document understanding.
For example, the data collected and processed by healthcare systems can include visual lab results, genetic sequencing reports, clinical trial forms, and other scanned documents. This presentation, if done right, can help doctors identify what they are looking at. AI algorithms that leverage multi-modal techniques (machine vision and optical character recognition) could augment the presentation of results and help improve medical diagnosis.
5. AI-enabled employee experience
Business leaders are starting to address concerns about the ability of AI to dehumanize jobs. This is driving interest in using AI to improve the employee experience.
AI could be useful in departments such as sales and customer care teams that are struggling to hire people. Along with robotic process automation, AI could help automate mundane tasks to free up the sales team for having a better conversation with customers. Additionally, it could be used to enhance employee training.
Read more: 9 Examples of Artificial Intelligence Transforming Business Today

Conclusion
Leveraging data and Artificial intelligence has grown due to the pandemic and businesses are digitally connected than before the lockdown.
At Fingent, we equip business leaders with insights, advice, and tools to achieve their business goals and build a future-proof organization. To learn more about how we fuel decision-makers to build successful organizations of tomorrow, contact us.
Stay up to date on what's new

About the Author

Featured Blogs








Stay up to date on
what's new



Talk To Our Experts
With the rise in the use of mobile phones and other smart devices, came the need for software to be ubiquitous. The amount of big data being dealt with, by enterprises across industries has also been on the rise. While we were busy wanting to access everything from everywhere, cloud computing was the technology that made it all manageable for companies and available for us.
Everyone wants to access everything from everywhere.
Cloud computing was introduced in 2000, to meet all of these demands, and provide people with ubiquitous, convenient and on-demand access to the network. It basically made use of a pool of shared configurable processing resources, such as the network and servers, that could be promptly provisioned and released with very little management efforts. The Internet of Things (IoT), also helped a great deal in keeping devices connected and enabled sharing of resources.

However, now we are faced with even higher levels of data, demand for flexible provisioning of resources as well as ubiquitous, on-demand access to the network. This explosion of data usage is what led to the emergence of a new, innovative computing mechanism that can provide healthy and strong real-time data analytics to clients, known as Fog Computing.
Fog computing, also known as fogging, is a kind of distributed computing system or infrastructure, in which only some of the application services are handled by the remote data centre (such as the cloud) while the rest of the services are handled at the network edge in a smart device. It is basically aimed at improving efficiencies and reducing the amount of data that is sent to the cloud for analysis, processing and storage.
While fog computing is often chosen for efficiency purposes, it can also be used for security and compliance reasons.
How it works
In a fog computing environment, most of the data processing happens in a smart mobile device, through a data hub, or on the edge of the network, through smart routers or other gateway devices.
In the normal case, a bundle of sensors generate immense volumes of data and send them to the cloud for processing and analysis. This process is not so efficient as it requires a huge bandwidth, not to mention the costs. The back-and-forth communication between the sensors and the cloud also affects the performance, leading to latency issues.
In fog computing, the analysis of data, decision-making as well as action, happen simultaneously, through IoT devices, and only the relevant data is pushed to the cloud for processing.
The architecture
A fog computing environment comprises three basic components:
- The Internet of Things (IoT) verticals or devices
- The Orchestration layer
- The Abstraction layer
All of these layers include physical as well as virtual systems that play an important role in the efficient and dynamic functioning of the fog computing system.
The IoT verticals consist of tenant applications or basically products which are rented for use. They support multi-tenancy, which enables multiple clients to host their application on a single server or a single fog computing instance. This is a very useful feature, as fog computing environments are all about flexibility and interoperability.
The orchestration layer is for data aggregation, decision making, data sharing, migration and policy management for fog computing. It consists of different APIs such as Data API and Orchestration layer API. The orchestration API holds the major analytics and intelligence services for fog computing. It also includes the policy management module, which is meant to facilitate secure sharing and communication in a distributed infrastructure.
The abstraction layer provides a uniform and programmable interface to the client. Like the cloud computing model, this layer makes use of virtualization technologies and provides generic APIs that clients can apply while creating applications to be hosted in a fog computing platform.
How does fog computing find its relevance in the real world?
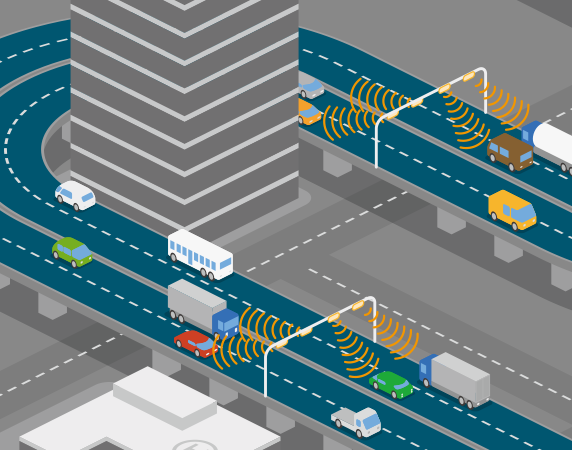
Consider the example of Smart Transportation Systems (STSs). The traffic light system in a state, say, Chicago, is equipped with sensors. On an occasion of celebration, the city is likely to experience a surge of traffic around specific times, depending on the occasion. As and when the traffic starts coming in, data gets collected from the different individual traffic lights. The application that is developed by the city to monitor traffic and adjust light patterns according to timings, which runs on each edge device, automatically takes control and changes light patterns in real-time. They work according to the traffic patterns and obstructions that rise and fall, collected by the sensors. Thus, traffic is monitored flawlessly.
In the normal case, there is not much traffic data being sent to the cloud on a daily basis for analysis and processing. The relevant data here is the data that is different from the usual scenario, that is on a day of celebration or a parade. Only this data is sent to the cloud and analyzed.
Why “fog” computing
The word fog in fog computing is intended to convey the fact that cloud computing and its advantages need to be brought closer to the data source, just like the meteorological relevance of the words fog, meaning clouds that are closer to the ground.
By all means, this technological innovation is something that the world really needs now. For all those businesses who have been waiting to find the perfect solution to your data issues, fog computing is definitely the way to go.
Image credits: Quotesgram, Atelier
Stay up to date on what's new
About the Author

Featured Blogs
Stay up to date on
what's new